IV. Discussion
A. Payment Caps
Both Pacific and the CLECs recommend an annual payment cap of thirty-six percent of the annual net return from local exchange service. Pacific Plan at 16; CLEC Plan at 12. This is the same percentage amount as implemented in four of the seven states that have obtained Section 271 approval, and is very close to the amounts in two other states.29 Verizon proposes smaller amounts.30 ORA proposes that there should be no cap. We are not persuaded by either ORA's or Verizon's presentations, and find no reason to depart from the precedent set in the states with Section 271 approval. Given the wide variation of payment amounts that the various plan proposals have generated in this proceeding, we believe it unwise to have no cap at all. Adopting a reduced amount could weaken the incentive effect of an incentives plan. Having no cap could subject an ILEC to unintended and virtually unlimited financial liability. Regarding ORA's concern that a cap could become a disincentive for performance improvements, the FCC has pointed out that no incentive plan needs to be sufficient, standing alone, to counterbalance an ILEC's incentive to discriminate.31 For the above reasons, we adopt the absolute caps defined as thirty-six percent of net return from local exchange service. These amounts will be calculated from the most recent ARMIS data and updated each year as soon as new data is available.
Pacific and the CLECs also propose "procedural caps" that limit the payment amounts without formal review. It is notable, however, that Verizon's monthly payment cap amounts are about the same as Pacific's procedural cap amounts when pro-rated by the two companies' different annual net return amounts.32 While we appreciate that our incentive plan should be self-executing without time consuming delays for reviews, we realize that unforeseen circumstances can arise that might place an ILEC in a financially liable situation that we might not intend. We will adopt procedural caps to help balance the need for self-executing payments with the need to protect against unintended financial liability. We agree with Pacific that these caps should have no exclusions.33 We will adopt procedural payment caps proportionate to those in New York and Texas because the California procedural payment caps should reflect the larger net return amounts at stake. We will adopt total monthly procedural payments caps of $15 million and $4.5 million for Pacific and Verizon, respectively. We will not adopt individual payment limits to individual CLECs, as we do not have sufficient record evidence and justification for such limits.
B. Mitigation
Since statistical tests do not eliminate all the error associated with performance assessment, several parties have pressed for provisions that reduce, or mitigate, the remaining error. These mitigation provisions essentially would allow a certain number of statistically-identified performance failures to be "forgiven," under the rationale that random variation, not inferior performance, would cause some failure identifications.
As discussed at length in D.01-01-037, our January 18, 2001 decision (Interim Opinion) establishing the statistical model for identifying deficient ILEC OSS performance, statistical tests can only provide estimates of the likelihood that a decision made about any given performance result might be in error. Interim Opinion at 59-69. Our Interim Opinion discussed the two fundamental types of error, Type I and Type II error. Type I error occurs when OSS processes for ILEC and CLEC customers operate at parity, but random variation causes us to identify the results as inferior for CLEC customers (non-parity). We set a cut-off point limiting the likelihood of a Type I error at 10 percent (0.10 critical alpha). Thus under ideal conditions, we will label parity performance as non-parity performance ten percent of the time. We did not set the critical alpha to be smaller because in doing so we increase Type II error. Type II error occurs when an OSS process for CLEC customers is inferior to that provided ILEC customers, yet our statistical decision identifies the results as parity performance. Our analyses determined that while Type I error was fixed at ten percent, Type II error far exceeded that amount. Interim Opinion, Appendix F. We instructed parties to propose ways to strike a better balance between Type I and Type II errors by proposing conditions for using a 0.20 critical alpha, which would decrease Type II errors.
However, the ILECs have only proposed provisions to reduce Type I error.34 Pacific and Verizon have proposed that failure identifications equal to the number of expected Type I errors be forgiven. For the monthly identifications, which have a ten percent critical alpha, Pacific and Verizon propose incentive payments only when the number of failure identifications exceeds ten percent.35 That is, at least ten percent would be forgiven. Pacific's Plan at 9-11; Verizon's Plan at 31-32. For the repeated failure identifications, Pacific proposes that a percentage equal to or greater than the resultant critical alpha be forgiven for three-month consecutive failure identifications, but not for six-month identifications. The resultant three-month failure identification critical alpha is 0.001, or 0.1 percent.36 Pacific does not propose mitigation for six-month failures because the resultant Type I error is negligible. Pacific Open. Comm. at 17. For example, with a monthly 0.10 critical alpha, the six-month resultant critical alpha would be 0.000001, or one-in-a-million.37 With approximately 4,000 tests per month, erroneous failure identifications would be extremely rare.
We must confront two issues in deciding whether to include a Type I mitigation component in the plan we establish today. First, any mitigation proposal must be viewed in the context of both Type I and Type II error. While Type I error mitigation may be rationally justified for reducing Type I errors under parity conditions, its justification is less clear under non-parity conditions. In short, we must examine how mitigation affects Type II error. Second, we must know that the statistical test assumptions behind the rationale for the mitigation plans are satisfied. For example, it was apparent during deliberations on the Interim Opinion that available statistical applications are not perfect. The question for us now is whether any un-met assumptions for those tests will distort the normal relationship between the critical alpha and the expected number of Type I errors.
1. Type II Error
As stated in the Interim Opinion, with Type I error fixed at ten percent, we found that estimates for Type II error were much higher.38 Since Type II error only can occur when OSS processes are not operating at parity, it is critical to examine current OSS performance. If we could be confident that parity exists, then we could be confident that mitigation plan use would be advised at least in the short term. However, if we find evidence for non-parity, then we must ensure that using a mitigation provision will not cause undue forgiveness of performance needing remediation.
On June 15, 2001, the Telecommunications Division issued a report examining Pacific's OSS performance for October through December 2000.39 Those months were the most recent months available when staff began its study. We now have the benefit of that report and the parties' comments. The report concluded that there were two sources of evidence for non-parity. First, the distribution of p-values provided evidence for both inferior and superior non-parity performance. Init. Rept. on OSS Perf. at 7-9. Second, the incidence of chronic performance failures provided additional evidence for inferior non-parity performance. Id. Because of this evidence indicating that Type II errors are likely, we are reluctant to mitigate Type I error further than we already have.40
Verizon is critical of our attention to Type II errors, but neglects to recognize the core problem. Verizon Open. Comm. at 23-28 (May 18, 2001). The problem with Type II errors is that poor performance to a CLEC is essentially ignored. To the contrary, Verizon asserts that a Type II error has "no adverse outcome to the CLEC or its customers." Id. at 26. To explain its views, Verizon presents a baseball strike zone as an analogy to ILEC OSS performance to ILEC and CLEC customers.41 In this analogy, a pitching machine represents ILEC OSS, and batters represent ILEC and CLEC customers. The better pitches, or "strikes," represent the better OSS performance, whereas the pitches outside the "strike zone" represent the poorer OSS performance. Since this analogy is supposed to illustrate parity performance results, the only relevant issue here is the comparison between the accuracy of "pitches" to CLEC customers versus the accuracy of "pitches" to ILEC customers. Performance is considered failing when CLEC customers' "pitches" are further from the center of the "plate" than are ILEC customers' "pitches." The illustration analogy for performance result sample sizes is the number of "pitches." Verizon does not adequately describe any OSS performance analogy for the differences in the size of the strike zone (Verizon Open. Comm. at 28), and we find no relevance in this proceeding for this element of their analogy.
We find that Verizon's analogy fails to support its conclusions regarding the impact of Type II errors. For example, on page 27 of its comments, Verizon asserts that it presents an illustration of a Type II error. However, in its "strike zone" analogy, Verizon asserts that when a CLEC receives two "perfect strikes" and the statistical test passes, a classic Type II error results. This analogy is inadequate. When actual sub-measure performance to CLEC customers is better than performance to ILEC customers as in this illustration, one-tailed statistical tests cannot fail. A one-tailed test can only find worse performance to be statistically significant. Thus at the level of performance to an individual CLEC, the basic premise of a Type II error, that worse performance not be identified as a failure, is not illustrated in Verizon's page 27 example.
The negative effect of a "classic" Type II error on a CLEC is best illustrated in Verizon's comments at pages 26 and 25. In the page 26 illustration, the CLEC receives worse service, but the test criteria are not met. Verizon agrees this is a Type II error. Verizon Open. Comm. at 25-26. Additionally, even though Verizon presents the illustration on page 25 to be an instance where a failure is statistically identified, because of the small sample the illustration is more likely to represent an instance where there is insufficient test power to identify this result as a failure. Thus, for this CLEC, it also would be a Type II error. The CLEC's customers would be disadvantaged and there would be no incentive payment to motivate the ILEC to provide better service. In summary, for the above reasons we are not persuaded by Verizon's argument that "the consequences of a Type II error result in no adverse outcome to the CLEC or its customers." Verizon Open. Comm. at 26.
We are concerned that the mitigation proposals reduce the number of Type I errors at the cost of producing more Type II errors. In every instance where an identified failure is "forgiven," performance to a CLEC's customers is worse than performance to the ILEC's customers. While at a theoretical level, some of these identifications may be Type I errors, we cannot ignore the fact that the inferior performance disadvantages the CLEC. Given this disadvantage, especially under overall non-parity conditions, an increment in the Type II error rate is likely.
2. Statistical Test Assumptions
Evidence from the distribution of p-values was the most controversial issue regarding OSS performance assessment. Most importantly, Pacific pointed out the fallacy of the assumption that under parity conditions the expected average Type I error incidence would equal the critical alpha level. Pacific stated that for this equality to occur, three conditions must be met:
"If we were to assume that:
1) all sub-measures operate exactly at parity,
2) all the assumptions of the statistical tests are satisfied, and
3) all the sample sizes are large,
then we should observe that 1% of sub-measures have p-values of .01, and so forth. But none of these assumptions is completely satisfied. It is very unlikely that all the sub-measures operate exactly at parity, nor is it likely that the statistical tests we want to use are completely appropriate to the problem, and it is certainly not true that all sample sizes are large. Therefore, it should not come as a surprise that the percentage of p-values less than .01 is not 1%." Pacific Reply Comm. OSS Results at 5-6 (July 6, 2001).
The evidence before us indicates that for the purposes of justifying current mitigation proposals, none of these assumptions are sufficiently satisfied. The tests we have selected, and the application of those tests, were based on the need for a practical application to existing conditions. For example, we cannot dictate sample sizes for any test as could be done in an academic application. Sample sizes are determined by many operational, business, and regulatory factors. Consequently, we must test using samples smaller than are optimal for the statistical tests. Another example is the use of statistical tests for average-based performance measures. While the log transformation required by the Interim Decision may bring the performance data distributions closer to normality and thus improve the t-test application, normality was not completely achieved.
Pacific and ORA both questioned staff's conclusions regarding the high incidence of p-values close to "1.0." Pacific Reply Comm. OSS Results at 8; ORA Open. Comm OSS Results at 5-8 (June 29, 2001). In its report, staff concluded that the dramatic departure from the expected proportions indicated that Pacific was often providing CLEC customers service so superior that performance results for these services were not subject to statistical failure identification. If this were the case, then it would increase the number of high p-values and reduce the number of expected low p-values. In the spirit of ongoing technical development stated in the report,42 the staff investigated this issue further. Upon request of staff, Pacific earlier had simulated parity OSS performance using the Interim Decision statistical model, Pacific's performance, and Pacific and CLEC sample sizes from December 2000. The premise of the investigation was that the simulation would forecast the possible outcomes if future performance were to improve or worsen. However, the simulations may also illustrate the effects of the departure from the optimal conditions needed to rely on the alpha/p-value distribution relationship, as illustrated below. Figure 3 shows three relationships. First, it shows the theoretical straight-line relationship between selected alpha levels and p-value cumulative percentages. Pacific's and Verizon's mitigation plans are based on this theoretical relationship. Second, the line depicting actual OSS performance begins above the theoretical line but continues mostly below that line. Third, the line depicting simulated parity performance begins and stays below the theoretical line.
Figure 3 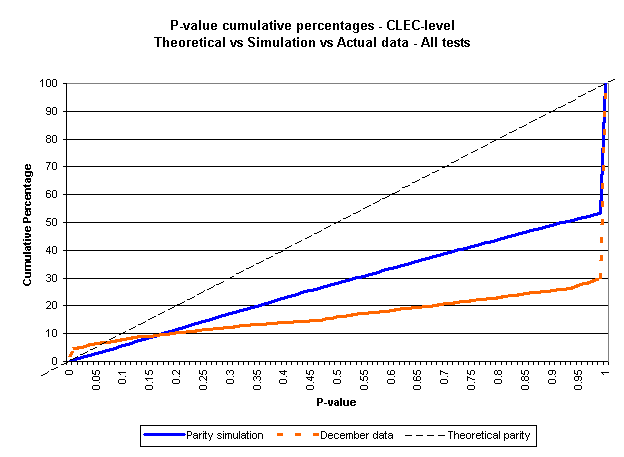
Several conclusions can be drawn from this graph. First, the considerable discrepancy between the parity simulation distribution and the theoretical distribution shows the effects of the departure from optimal statistical conditions. This provides evidence that we cannot simply "forgive" a percentage of failures equal to, or greater than, the critical alpha level. For example, at a 0.10 critical alpha level, using the Interim Opinion tests and actual performance parameters, the graph shows that we should only expect about five percent failure identifications overall. Second, to the extent that the simulations are accurate, the similarity between the simulation and actual performance distributions shows that much of the high incidence of "better service" results is actually an artifact of the statistical test applications. All of the departure from the theoretical cumulative distribution cannot be attributed to "better service" as suggested in staff's June 15, 2001 report. Init. Rept. OSS Perf. at 9. Additionally, the differences between the simulation and the actual performance distributions represents poorer and better than parity service at the left and right portions of the graph, respectively.
Although we have evidence that statistical test artifacts cause much of the departure from the theoretical optimal cumulative p-value distribution, we are not persuaded by some parties' comments that the provision of exceptionally good service does not affect mitigation appropriateness. Specifically, Pacific asserts that to not forgive 10 percent of the statistically identified failures because an ILEC otherwise provided "ultra-good service" would be "perverse." Pacific Reply Comm. OSS Results at 2-4. Pacific argues that "the notion that exemplary performance should decrease the allowance for random variation is unfounded, unfair, and counter to the principles of a fair incentive plan."43
We disagree with Pacific's assertions and arguments here for two fundamental reasons. First, the purpose of this incentive plan is not to reward or credit an ILEC for giving an OSS competitive advantage to the CLECs. The limited purpose is to ensure that an ILEC does not present OSS barriers to the CLECs. The role of an incentive plan is to ensure an ILEC removes all OSS barriers, regardless of whether an ILEC chooses to otherwise provide exceptionally better service. To allow provision of exceptionally better service to offset instances of poor service would be contrary to our goals here.44 Additionally, it would set up rewards for gaming behavior. For example, an ILEC could give exceptionally good service for all but the most profitable ten percent of the sub-measures, and provide real OSS barriers for the remaining ten percent. With a ten percent mitigation plan, there would be no payments even for such purposeful anti-competitive behavior. In fact, a ten percent mitigation plan could function as an incentive for gaming behavior.
We also do not accept Pacific's reasoning when it asserts that ten-percent forgiveness is warranted in two scenarios: (1) a "perfect parity" scenario with ten percent "ultra-superior service," eighty percent "parity service" and ten percent "missed" due to random variation, and (2) a scenario with ninety percent "ultra superior" service and ten percent identified as "missed." Pacific Reply Comm. OSS Results at 3. Pacific's illustration is reproduced in Figure 4.
FIGURE 4
Level of Service | |||
Scenario 1 |
Ultra-Superior |
Parity |
Missed |
Scenario 2 |
Ultra-Superior |
Missed | |
First, we find Pacific's arguments irrelevant because they assume optimal statistical test conditions that do not exist in the actual plan application as described earlier in our discussion. Second, Pacific's implication that the ten percent identified as "missed" should be forgiven in both scenarios neglects the premise of mitigation. By definition, the sole purpose of random variation mitigation provisions is to mitigate any payment liabilities from failures identified solely because of random variation. Even if we assume the necessary statistical conditions exist in these scenarios, and that the ten percent should be forgiven in Scenario 1, the logic does not extend to Scenario 2. Scenario 2 is based on the premise that ninety percent of the service is "so good that random variation has been eliminated as a potential cause for missing a sub-measure." Id. at 2, fn. 3. Thus, while 100 percent of the measures in Scenario 1 are subject to random variation,45 only ten percent of the Scenario 2 measures are subject to random variation. Given the assumptions in these scenarios and adhering to the underlying principle that ten percent of the measures subject to random variation should be "forgiven," we should forgive ten percent in Scenario 1 and one percent (ten percent of ten percent) or less in Scenario 2.46 In other words, zero percent of the OSS service in Scenario 1 is discriminatory, whereas at least nine percent is discriminatory in Scenario 2. We would expect the hypothetical ILEC to make incentive payments on nearly all the missed measures in Scenario 2. In conclusion, we find that the preponderance of evidence indicates that a mitigation provision that "forgives" a percentage of statistically identified failures equal to or greater than the critical alpha level is not appropriate under current circumstances.
An apparent alternative would be to compare the actual performance distribution to the simulation distribution. However, there are several problems with this alternative. First, different statistical tests will produce different distributions. We would need to consider additional research determining the expected distribution for each different statistical application and then compare the relevant actual performance to each distribution. That research is not sufficiently developed at this time. Second, the discrepancy between the theoretical cumulative distribution and the actual cumulative distribution changes with different critical alpha levels. For example, there are approximate discrepancies of 4.5, 4.2, 2.6, 1.0, and -0.8 percent at the 0.01, 0.05, 0.10, and 0.15, and 0.20 critical alphas, respectively. Since we based our selection of the 0.10 critical alpha level on other factors, it makes the mitigation plan outcomes somewhat arbitrary. The mitigation outcomes also become somewhat counterintuitive to the extent that as we select a larger critical alpha to detect more failures, we decrease the number of failures treated by the plan. For example, at an alpha level of 0.01 we would identify 4.5 percent of the results for incentive payments, whereas if we increased the alpha level to 0.20, we would not identify any failures for incentive payments. Third, the integrity of using the comparison is completely dependent on the accuracy of the simulations. We do not have sufficient evidence of accuracy to depend on these simulations for appropriate mitigation levels. For these reasons we decline to use the simulations as a standard for parity.47
The ILECs' most compelling argument for their mitigation proposals is that without them, when their OSS processes are operating at parity they will be inappropriately penalized. While we agree with the need for some additional protection when parity performance has been achieved, we note that parity has not yet been achieved. We assume that under all the scrutiny that Pacific has experienced since July of 1999, when the performance measures were implemented, that Pacific has been trying to get its OSS processes to operate at parity. Given that they have not been able to do so in over twenty-one months makes us doubt that parity will be achieved in the next few months. Since the implementation we order today will in effect be a six-month initial implementation period, it is not likely that Pacific will be placed in the unfortunate situation of parity operation without random variation mitigation during this time.
For all the above reasons, we decline to adopt a mitigation proposal at this time. However, we will direct parties to continue mitigation provision development for our consideration for future use. Parties should address all the issues raised above as they develop and present new proposals. If at any time in the future there is compelling evidence that complete parity has been achieved, or that a suitable mitigation metric has been developed, then we intend to include appropriate mitigation if it presents no problems should performance deteriorate, or "backslide."
C. Conditional 0.20 Critical Alpha
In the Interim Opinion we directed parties to propose conditions where a larger alpha, 0.20, would be used to increase the power of the statistical tests. We will not adopt any party's specific proposal. We will not adopt Pacific's proposal because it is only used for the larger sample sizes (aggregate samples, greater than 30), and is used in repeated failure situations where the net resulting critical alpha is 0.008, much smaller than the unconditional standard, 0.10. To increase test power as we intended, a larger alpha is best used for the smaller, rather than larger samples. Additionally, since a consecutive-failure identification requirement decreases Type I error at the expense of Type II error and, as used by Pacific, is contrary to the more balanced situation we seek, we decline to use the Pacific proposal. The Verizon proposal is virtually the same and we decline to use it for the same reasons. However, we do appreciate the fact that both Pacific and Verizon have increased the critical alpha for the individual tests that make up the consecutive-failure identifications. Without the increase to the monthly 0.20 alpha level, the net critical alpha would have been one-eighth as large, 0.001 versus 0.008.
The CLEC proposal is consistent with the guidelines we established in the Interim Opinion. The CLECs would apply the 0.20 critical alpha only for small sample conditions, and as a consequence would increase test power where it is most often needed. However, we also wish to utilize other available information that will enhance the benefit of using a larger critical alpha by more closely targeting situations where it will be most helpful. Such information exists in the aggregate analyses. These analyses have larger sample sizes and thus are better at detecting non-parity (true failures) without increasing Type I error. Since increased test power and decreased Type II error are only helpful in true non-parity situations,48 any information indicating non-parity will be helpful in targeting our conditional alpha. So if we use the larger critical alpha for CLEC-level results only where the corresponding industry aggregate fails, we are likely to better target the appropriate situation for increasing test power.
We conclude that since increased power is most appropriate for small samples, for tests for repeated failures, and when there is information indicating sub-measure non-parity, that we will adopt the following provision: A 0.20 alpha will be used under the following circumstances:49
(1) When sample sizes are less than 30 for single-month individual CLEC tests where the aggregate sub-measure test indicates non-parity.
(2) For all tests for repeated failures.
We also find merit in the CLECs' proposal to decrease Type I error where it is most likely to occur, namely large samples. However, the CLECs' propose applying the smaller alpha level to all Tier II (aggregate level) statistical tests, regardless of actual sample size. Since there are still many small samples at the aggregate level, we find the proposal does not target the problem as closely as we would prefer. Given that a smaller critical alpha is most warranted for larger samples, and for samples where information suggests parity, we will adopt a five percent critical alpha under the following conditions:
(1) When sample sizes are 100 or greater for single-month individual CLEC tests where the aggregate sub-measure test indicates parity.
(2) When single-month sample sizes are 500 or greater.
D. Payment Amounts
Parties have presented economic justifications for the incentive payment amounts their respective plans would produce. Each justification makes several assumptions about economic harm to the CLECs. However, since variation in these assumptions and the potential affect of unrecognized variables could cause large changes in the economic estimates, we are reluctant to base the payment amounts on these estimates. For example, Pacific assumes that poor performance to CLEC customers would cause the CLEC to lose ten percent of those customers. Pacific's estimates are based on the net income that a CLEC would lose from each customer. We are concerned that higher percentages of customers could be lost, and in the span of time it would take for Pacific to correct the performance, a CLEC could lose so many customers that it would not be able to stay in business. The economic harm would far outweigh the individual customer profit amounts. For example, Pacific estimates that with a thirty percent failure rate, the economic harm to the CLECs would only be measured in the profit loss from ten percent of the CLEC customers leaving the CLEC, and estimates that loss to be $219,080. Pacific Open. Comm. at 8, 11. We are not persuaded that the assumptions in this estimate are sufficiently developed for us to decide that such poor performance could be affected by such a tiny portion of Pacific's local service net return. This amount represents about four-hundredths of one percent of the payment cap.50 Additionally, the incentive payment Pacific offers in severe non-parity conditions pales in comparison to the failure rate and the net return. Pacific offers a $7 million monthly payment for a thirty-eight percent performance failure rate. Such a failure rate is likely to severely impact competition, yet the payment represents only about six percent of Pacific's local service net return.51
Parties have proposed specific payment amounts that are justified by different assumptions and calculations. These payment amounts vary widely between the plans, and for us to determine which plan has the most appropriate payment amount would require examination and verification of these assumptions and any unstated variables as discussed above. Given the need to move Pacific's 271 Section application process forward, we are not in a position to thoroughly uncover and examine all these issues at this time. However, Section 271 approvals in other states provide some guidance. There is a growing consensus that the overall cap for state performance incentives plans should be thirty-six percent of net return from local exchange service. We will adopt this amount for Pacific's incentive plan as discussed above. Yet for this cap to be a functional cap instead of just a hypothetical figure, there must be a way for this amount to be generated. In the extreme, we believe no party would object to the total cap being paid when an ILEC fails 100% of the performance measurements. This provides us with an anchor on which to base payment amounts for less deficient performance. For example, if we chose a linear method, ten percent of the cap would be paid for ten percent deficient performance. We find that this scaling method is consistent with the FCC's view of incentive payment amounts:
[I]t is important to assess whether liability under an enforcement mechanism such as the APAP would actually accrue at meaningful and significant levels when performance standards are missed. Indeed, an overall liability amount would be meaningless if there is no likelihood that payments would approach this amount, even in instances of widespread performance failure. FCC BANY Order at ¶ 437.
However, for several reasons we favor Pacific's proposed curvilinear relationship between payment amounts and performance. The meaning of smaller percentages of deficient performance is ambiguous relative to larger percentages. As discussed above, considerable analysis must be performed to understand the actual impact of 10 percent missed performance measures, whereas with levels of 20 percent, 30 percent, and 40 percent missed measures it becomes increasingly clear that parity is not being provided. Additionally, we suspect that after additional evidence is provided and analyzed, that some mitigation may be warranted. For these reasons we will adopt Pacific's curvilinear escalating payment concept.
However, using the payment cap as our guide, we find that Pacific's specific payment amounts are insufficient. First, we believe that the payment cap should be reached well before 100 percent of the aggregate-level measures are being missed. While it is difficult to establish an exact missed performance percentage, we find it reasonable to conclude that when there are two missed sub-measures for every one that passes, the full cap should be paid. Given the low power of many tests, at this level of performance it is highly likely that the true percentage of misses would be closer to 100 percent. Therefore, we will anchor the payment levels on the principles that 100 percent of the cap should be paid when sixty-seven percent of the performance measures are missed, and that payments should increase in a curvilinear fashion.
Nevertheless, to adapt this "anchor" to Pacific's treatment of ordinary failure pervasiveness, we recognize that tests at the individual CLEC level will not show as high a failure rate as the industry aggregate level. Examining data from October through December 2000, we find that the aggregate level statistical failure rate is approximately 50 percent higher than the CLEC-level rate.52 This relative percentage is corroborated by more recent data when benchmarks are also included.53 For the above reasons, and recognizing the variability in the relative percentages, we find a reasonable "anchor" for basing the full monthly cap payment on single-month CLEC-level failure rates to be 50 percent.
We also acknowledge and address the ambiguity inherent in the performance measures, benchmarks, and statistical tests by requiring lower relative penalty amounts for lower failure rates and by increasing the penalty rates as performance worsens. While our payment levels are lower than those proposed by some parties, they are higher than Pacific's proposals to better coincide with the full "liability at risk," to better account for the potential damage to competition, and to better motivate parity performance. In conclusion, we are persuaded that Pacific's increasingly higher penalty rates (curvilinear) are more appropriate for an incentive plan than the CLECs' more uniformly increasing rates (linear).
Figure 5 illustrates the guide we will use for payment amounts:54
![]()
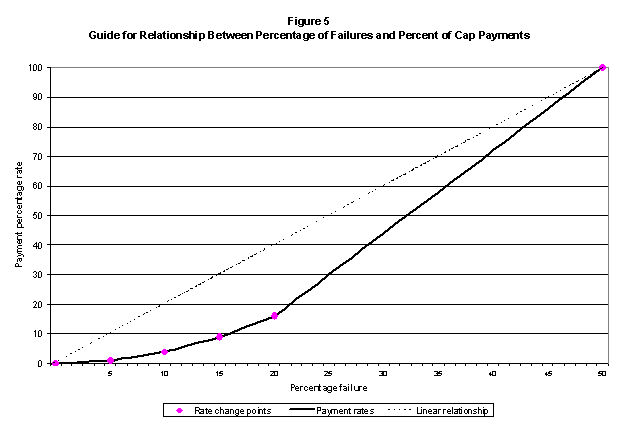
![]()
The penalty rates are anchored at no payment for zero to one percent failure rates, to a 100 percent cap payment for a 50 percent single-month CLEC-level failure rate, with interim rates starting low and increasing. Specifically, our guide will be the following payment rates:
TABLE 1
Failure rate |
Payment rate | |
Equal to or greater than |
But less than |
|
0 |
1 |
Zero percent |
1 |
5 |
Linearly increasing from zero to one percent |
5 |
10 |
Linearly increasing from one to four percent |
10 |
15 |
Linearly increasing from four to nine percent |
15 |
20 |
Linearly increasing from nine to sixteen percent |
20 |
50 |
Linearly increasing from sixteen to 100 percent |
50 |
100 |
100 percent |
It may not be possible for us to exactly match this rate schedule because the total monthly payment amounts are generated from multiple individual origins. However, to the extent possible, the plan we adopt today will be based on this rate structure. Examples of rates we will use as a guide are included as Appendix F. This table is based on the principles proposed in Pacific's plan. As deficient performance becomes more pervasive, the payment amounts increase.
In contrast to Pacific's payment amounts, the amounts we adopt increase continuously based on the percentage failure rate. Specifically, the payment for each single-month individual CLEC performance failure will be a base amount multiplied by the overall single-month CLEC-level failure rate.55 For example, with an overall single-month CLEC-level failure rate of eight percent, and a base amount of $40, the basic payment would be $320. The payments for chronic, extended, and Tier II chronic failures are 5, 10, and 25 times the basic payment. Examples of payments for different failure rates are presented in Appendix G. Compared to Pacific's proposal, the payment amounts we adopt for single-month sub-measure failures begin lower for the smallest percentages, but generally are the same as Pacific's amounts. The amounts we adopt continuously increase, in contrast to Pacific's amounts, which increase in four steps. Estimates of different total payment amounts generated by these individual payment amounts are presented in Appendix G. These amounts generally follow the curvilinear trend that we seek. They are generally less than the target amounts, especially at the lower failure rates. However, the table amounts do not incorporate the other changes we will make to the overall plan. Those changes, such as our conditional alpha provision, will likely raise these amounts.
A cursory review of incentive plan outcomes in New York and Texas indicates that our plan is certainly in the same "ballpark." However, because of the many differences in the three plans it is not possible to directly compare failure rates and payment amounts at more than a "ballpark" level. The three state plans have different numbers of measures, different weightings for outcomes, and different ways to assess outcomes, among other differences that make direct comparisons difficult. For the sake of "ballpark" background information we present a table of failure rates and actual or estimated payment amounts for the New York and Texas state plans in Appendix H.
E. Repeated Failures
Pacific, the CLECs, and Verizon all propose that consecutive-month failures be identified for incentive payments. We agree that repeatedly deficient performance should be addressed. However, we share the concern that the FCC has voiced regarding local competition "gaming." "Gaming" refers to possible strategic behavior that either incurs or avoids payments that are not correlated to reasonable OSS performance effects.56
An ILEC might be able to "game" the repeated-failure provisions.57 Under the proposed repeated-failure treatments, if an ILEC had sufficient control over its OSS processes it could strategically avoid any repeated-failure payments by giving deficient service every other month or never for more than two consecutive months. If this occurs, it would likely be more of a problem for the "extended chronic" identifications, which require six-month consecutive deficient performance. For example, if the test passed in the sixth month, no identification could be made until six additional consecutive monthly tests failed.
Another concern we have for the repeated-failure assessments is that they decrease Type I error at the expense of Type II error. For example, using a single-month test with a Type I error cutoff of 0.20 and a Type II error of 0.30, a failure identification decision based on three consecutive monthly failures would have a net result with a Type I error limit of 0.008 and a Type II error of 0.657.58 Intuitively, the effect on Type I error is illustrated by the fact that to fail to identify good performance as good, there must be three misses in a row, and the resultant probability is lower. For example, when flipping a coin with "heads" representing a Type I error, getting a coin to come up "heads" three times in three tosses is far less likely than getting the coin to come up "heads" in just one toss.59 On the other hand, the effect on Type II error is illustrated by the fact that to fail to identify bad performance as bad, there only needs to be at least one miss out of three, and the resultant probability is higher. For example, when flipping a coin with "heads" representing a Type II error, getting the coin to come up "heads" at least once in three tosses is far more likely than getting a coin to come up "heads" in just one toss.60
As with the gaming possibility, the extended chronic failure test is the most susceptible to this increased Type II error problem. Even with relatively very high power such as a seventy percent chance to detect poor performance when it occurs (a Type II error of 0.30 for a single test), the net Type II error when six consecutive statistical test failures are required is 0.882. In other words, under non-parity conditions a Type II error is virtually assured.
Because of this imbalance between these two types of errors, we will implement two provisions designed to mitigate the discrepancy. First, for the extended chronic failures to be identified, we will only require five out of six consecutive tests to fail.61 Second, to ensure that parity performance has been achieved subsequent to a repeated-failure identification, we will require two consecutive months to pass before sub-measure failure payments are returned to non-chronic or non-extended chronic payment levels. The CLECs proposed this provision for their chronic failure treatment (CLEC Plan at 9), and we agree that it is an appropriate provision to reduce the chances of gaming and to increase the chances of identifying and correcting poor performance when it occurs.
Pacific proposes that when there is no activity by a CLEC or CLEC aggregate62 for a month during an otherwise consecutive "run" of performance failures, that the "run" not be considered a repeated failure. Pacific Repl. Comm. at 4-5 (June 1, 2001). The CLECs disagree, and Verizon's plan ignores such a month without activity. CLEC Open. Comm. at 9 (May 11, 2001); Verizon Assumptions documentation (May 16, 2001)63 For example, Pacific would not consider the performance failures during the months of January through April except for inactivity in March, to constitute a repeated (chronic) failure, whereas the CLECs and Verizon would identify it as a repeated failure. We wish to avoid the situation where the only performance received by a CLEC or the CLEC industry on a particular submeasure is failing, yet payments stay at a one-month failure payment amount as if it were an isolated incident. Therefore, we will adopt the CLEC-Verizon position, except that a gap of inactivity of longer than three months will interrupt the "run" unless the sub-measure is one that is identified as having no minimum sample size.
F. Severity
Adjustments for the severity of performance failures can enhance an incentive plan's ability to target the most deficient performance by making incentive payments greater for the more severe failures. While Pacific's plan does not address severity, the CLECs', Verizon's, and ORA's plan include severity adjustments.
The CLECs' and ORA's plans indirectly address severity by using the probability statistic, Z, as a surrogate for severity. All other things being equal, as a performance failure becomes more severe, the corresponding Z-statistic becomes larger (smaller p-values). However, all things are not equal. For example, the Z-statistic is also influenced by sample size. This influence can easily overshadow actual performance differences to the point where a less severe performance result can have a larger Z-statistic than a much worse result if its sample size is sufficiently larger. Citing one actual sub-measure example, an ILEC took an average of nine days to provision service for its own retail customers, an average of 15 days for CLEC A's customers, and an average of 12 days for CLEC B's customers. With sample sizes of 9 and 118 cases for CLEC A and B, respectively, the statistical test produced a Z-statistic of 2.0 for CLEC A and 3.5 for CLEC B.64 Even though performance was worse for CLEC A, CLEC B received a larger Z-statistic because of the larger sample size. This is simply because we can have greater confidence (higher Z-statistics, lower p-values) in results for larger samples. However, the CLEC and ORA severity proposals would identify CLEC B's less severe results as more severe than CLEC A's results even though this is not the case. Because of the possible confounding with other variables, such as sample size, we decline to adopt the severity adjustment proposals of either the CLECs or ORA.
In contrast, Verizon's plan addresses severity by calculating how much worse performance is to CLEC customers than to Verizon's own customers. In general, Verizon's plan calculates the percentage of customers who receive service worse than the average ILEC customer (or the benchmark), and then uses that number as a measure of severity to adjust payment amounts. The severity measure is an integral part of Verizon's transaction-based incentive payment system, and we find it difficult to convert to the sub-measure-based approach we adopt. As a consequence, we decline to adopt Verizon's severity adjustments. However, we appreciate these development efforts and encourage Verizon to continue this development in the next phase of the incentive plan.
We encourage all parties to continue to develop severity measures for the incentive plan. Insofar as a severity adjustment might scale payments to the degree of harm and help ILECs focus on the most needed OSS enhancements, we are interested in adopting such adjustments in the future.
G. Statistical Testing for Benchmarks
Pacific proposes statistical testing for benchmarks and focuses its justification on reducing random variation effects on assessments with underlying compliant conditions. Pacific Open. Comm. at 19-21 (May 18, 2001). However, for us to fairly implement such a treatment, we would need to also examine the effect of random variation on assessments with underlying non-compliant conditions. We struck a balance between the two effect types, or error, in the Interim Opinion, and without additional study and justification we will not change that balance. Interim Opinion at 116-124. Consequently, we will not apply statistical testing to benchmark sub-measure results.
H. Functionality
An important distinction between the plans is their functionality in fundamental areas. A plan should be consistent across time and should reflect differences in performance. Since we will adopt one plan for both ILECs, we need to know that the plan we select will produce equitable outcomes for both ILECs. The plans should also produce payment amount levels that are consistent with the "curvilinear" payment amount guide we established above.
Pacific's plan provides relatively consistent output and is correlated to aggregate failure rates for the year 2000. The other plans' payment amounts are either not significantly correlated to aggregate failure rates and/or are inconsistent month-to-month.65 Since Pacific's plan is not based on volume metrics, the payment amounts can be adjusted for Pacific and Verizon to account for the different size of the two companies and to match the "curvilinear" payment guide.
The CLEC plan payment amounts are much higher than our payment amount guide. The plan does not appear to be as sensitive to overall failure rates as the Pacific plan. Verizon's and ORA's plans are inconsistent from month-to-month, producing wide variations in payment amounts that are not related to the relatively small variations in aggregate failure rates. Other problems with severity and volume-related metrics make the Verizon, CLEC, and ORA plans difficult to implement consistent with the criteria we have discussed in this decision.
For the above reasons, we find that Pacific provides the best base plan. However, as discussed, we find that several significant modifications are necessary for the plan to be consistent with the criteria we deem important. We will adopt Pacific's basic plan with these major modifications.
I. Measures
Not all performance measures will be subject to incentive payments. In the February 2001 workshops the parties referred to an existing agreement regarding excluded measures. At staff request, Verizon later submitted the list of performance measures and sub-measures to be excluded from the incentive payment plans.66 That document is included in the record in this proceeding and is reproduced here as Appendix I. However, in their recent comments, Verizon proposes only a subset of these measures be used because other measures are correlated to the remaining set. Their rationale is that paying on a measure as well as a correlated measure results in duplicative payments. Verizon Plan at 4 (May 4, 2001). However, since the plan we adopt is scaled to Pacific's and Verizon's individual payment caps, their total payment amounts are no different than if fewer measures were used. Where there may be correlated measures, there is still value in multiple measurements, unless the measures have perfect or near-perfect correlations.67 We have no evidence to suggest that these performance measures are so highly correlated that they add no value to the assessment. Additionally, these measures were established in a collaborative process and we do not wish to depart from the conclusions in that collaboration because of the wishes of one party. For the above reasons, we will use all performance measures except for those that the parties have agreed to exclude as listed in 2000 GTE Workpaper #13.
J. Remedy Exclusivity
Both Pacific and Verizon ask that payments made under the adopted incentives plan be the exclusive remedy for deficient performance. The CLECs oppose exclusivity, however, and point out that Pacific and the CLECs agreed in 1998 that performance incentives would not be the sole remedy. CLEC Open. Comm. at 36.68
Pacific now supports payment exclusivity asserting that performance related payments must be defined as liquidated damages or penalties, and that penalties are unenforceable under California law. Pacific Open. Comm. at 26. Pacific asserts that as a consequence, "performance-related contractual payments must be considered liquidated damages." Id.
Verizon also takes the position that payments should be the sole remedy and should be defined as liquidated damages. Verizon Reply Comm. at 29. Verizon argues that to define payments as penalties would require that penalties be paid only under the provisions of Pub. Util. Code § 2104, which would require Superior Court action. Verizon argues that as a consequence, payments defined as penalties could not be "self-executing" as intended in the plans. Verizon further argues that since a self-executing plan cannot impose monetary penalties, any payments must be a "reasonable estimate of fair compensation" and thus must be treated as liquidated damages as the sole remedy for failed OSS performance. Verizon fears that without this protection a CLEC will be able to automatically recover compensation for deficient OSS performance and then sue for further damage payments. Verizon Reply Comm. at 29-33.
The CLECs argue that neither the FCC nor the Commission in this proceeding has sought incentive payments as "fair compensation," and that payments should be treated as penalties. CLEC Open. Comm. at 36-40. The CLECs distinguish between the ILECs' asserted goals of "fair compensation" and the goal of the plan as an "incentive" mechanism. The CLECs' arguments imply that "fair compensation" for losses due to OSS disadvantages would not provide sufficient incentive for an ILEC to provide OSS parity. Id. As a consequence, the CLECs argue that incentive payments must be deemed "penalties" which are not the exclusive remedy for deficient OSS performance to their customers. Id. at 39.
We are not persuaded by Pacific's and Verizon's arguments that this Commission should declare the incentive payments to be the exclusive remedy for deficient performance. In fact, we note that in its BANY Order the FCC asserted that "[i]t is not necessary that the state [enforcement] mechanisms alone provide full protection against potential anti-competitive behavior by the incumbent."69 The FCC further acknowledged that the ILEC might be subject to "payment of liquidated damages through many of its individual interconnection agreements" and "risks liability through antitrust and other private causes of action if it performs in an unlawfully discriminatory manner."70
We likewise reject Verizon's insistence that Pub. Util. Code § 2104 compels us to decree the incentive payments to be liquidated damages and the CLECs' exclusive remedy for discriminatory ILEC performance. Given the level at which we set the payments today, we consider them to be an inducement of appropriate market behavior rather than penalties.71 This record does not support the determination that the incentive payments will be "fair compensation" to a harmed CLEC. What constitutes fair compensation to the CLECs would be extremely difficult to calculate. Moreover, the goal of the proceeding is not to provide "insurance" payments to a CLEC (that it will receive fair compensation while it is being discriminated against), but to ensure that there is a competitive market. Significantly, this Commission has the authority to award reparations, not damages. See Garcia v. PT&T Co. 3 CPUC2d 534 (1980). In addition, we have crafted this plan in concert with the parties in order to implement the federally mandated restructuring of the local market. The self-executing enforcement aspects of the plan establish a showing to the FCC of compliance with our performance standards in satisfaction of the requirements of Sections 251 and 271.
K. Implementation
The ILECs in particular will have a number of tasks to complete before the plan we adopt can be implemented. They must establish procedures for monitoring, assessment, reporting, and making payments. The CLECs and the ILECs must prepare for possible dispute resolution. Some of the performance assessment requirements may require modification in view of Pacific's experience with Interim Opinion implementation. To aid the parties in these implementation tasks, we establish specific requirements. Some of these requirements are in response to issues raised in the various briefs. Other issues may not have been formally presented, but must be addressed in order to expedite the implementation process. Parties' comments on this decision draft will likely help guide us as we specify these requirements.
1. Forecasting
Pacific and the CLECs have agreed that forecasts of OSS demand are important to smooth and efficient OSS operation, and that inadequate CLEC forecasts should be cause for excluding incentive payments in the event that deficient OSS performance resulted from such forecasts. CLEC Plan at 18-19; Pacific Plan at 20-21. ORA is concerned that Pacific may unilaterally define forecast inadequacy. ORA Open. Comm. at 7. However, the CLECs have agreed to provide forecasts as proposed by Pacific. CLEC Plan at 18-19; Pacific Plan at 20-21. As the CLECs and the ILECs are in the best position to know how to implement forecasts for the purposes of OSS operation, we adopt these provisions.
2. Monitoring and Reporting
The ILECs will monitor OSS performance continuously. In the performance measurements proceeding we have established the performance measures on which the incentive payments will be based as well as the performance measures that are used solely for diagnostic purposes. These measures undergo periodic review and updating. D.01-05-087 (May 24, 2001) (JPSA Opinion).
The JPSA Opinion also established performance-reporting requirements. Pacific is now required to report performance results by the twentieth calendar day of the month succeeding the reporting period. JPSA Opinion at 106.72
3. Payments
Pacific proposes to make payments within thirty days of the due date of the performance results report. Pacific Plan at 16. For example, performance reports for August 2001 would be due on or before September 20, 2001. Payments arising from the August 2001 performance results would be due on or before September 19, 2001. No parties oppose Pacific's proposed payment schedule. As the schedule has no opposition, and seems to provide a reasonable amount of time to ensure accurate payment, we will adopt it as proposed.
4. Payment Recipients
Two goals will guide our selection of who receives the performance incentives plan payments. First, the plan should provide some compensation to each CLEC when it receives poor performance as established by the performance criteria and payment structures we have established in this Decision and D.01-01-037. Second, since the payments to the CLECs are not likely to create sufficient incentives for optimal OSS behavior, the overall industry-wide effect of OSS performance on competition should generate additional incentive payments. This will be especially true while CLEC market share is low. With a small percentage of the market, compensation for poor performance necessarily based on that small percentage is not likely to provide much incentive to the ILECs. Payments could simply end up being seen as the "cost of doing business," and not be effective in motivating optimal OSS performance. Additional payments based on overall industry effects will provide an incentive for this potential problem.
To address the first goal, we will require that payments go directly to each CLEC whose monthly sub-measure results the plan identifies as warranting payment for failing performance. These payments will be termed Tier I payments and include payments for individual CLEC results, small sample aggregate CLEC results, and CLEC results where the only logical measure is at the industry level.73 In the Tier I aggregate results, only those CLECs whose customers receive worse performance than the ILEC customers will be eligible for payments.
The second goal, incentive payments based on overall industry effects, is achieved through incentive payments generated by industry-wide ILEC OSS performance. Individual CLEC results are aggregated into one performance result for each sub-measure. Payments are generated from each sub-measure with failing performance. These payments will be termed Tier II payments. Recognizing that the total payment made by an ILEC is designed to be an incentive for good OSS performance, and thus will exceed the measure of CLEC economic harm, it is appropriate for these payments to go to a public fund as proposed by Pacific and the CLECs, or to the ratepayers as proposed by ORA. See supra.
ORA proposes that incentive payments go to ratepayers through Pacific's Rule 33 74 and Verizon's Tariff 38 75 surcharge and surcredit mechanisms. ORA's rationale is that incentive payments should go to ratepayers because the ratepayers paid for the infrastructure changes and upgrades that the ILECs made to effectuate local exchange competition.76 ORA argues that since ratepayers are making a significant investment in the ILECs' OSS infrastructures, it follows that they should receive incentive payments, which are directly related to the extent that those infrastructures do not perform as they should. ORA argues that to the extent that OSS performance presents competition barriers, not only will ratepayers have borne the cost for the ILECs' OSS-related infrastructure, they also will not have received the economic and social benefits of competition which motivated the 1996 Telecommunications Act.
Under ORA's plan, incentive payments would be calculated on an annual basis and paid in monthly increments during the following year through the Rule 33 and Tariff 38 mechanisms. As authorized in D.00-09-037 and D.01-09-063, Rule 33 and Tariff 38 billing surcharges are used to compensate Pacific and Verizon for the costs they incurred to implement local competition. The Rule 33/Tariff 38 billing mechanisms would flow the incentive payments back to all ratepayers, including CLECs and inter-exchange carriers, in the same proportion as the local competition implementation infrastructure costs that each customer class (e.g. toll, access, and exchange) is paying through annual surcharges. ORA points out that the Commission adopted "Service Quality Assurance Mechanisms" for both Citizens Telephone (D.95-11-024) and GTE California, Inc., (D.94-06-011) in which violations of the service standards resulted in surcredits to ratepayers, and that CPUC General Order 133 (GO-133) also provides for ratepayer surcredits in the event of poor service by a regulated telephone company.
Exogenous cost changes and other regulatory surcharges and surcredits are included in the annual Price Cap filings that Pacific and Verizon are required to make every October. In the annual filings, the utilities identify specific cost changes (increases and decreases) that occurred in the prior period (e.g., from October 1 through September 30). These cost changes are combined and summed to determine the dollar amount of surcredits or surcharges to be reflected on a customer's monthly bills during the next calendar year. Surcredits and surcharges, such as Pacific's merger savings and local competition implementation costs, are distributed between three groups of services in proportion to each group's share of Pacific's total annual billing base. These groups are IntraLATA Exchange, IntraLATA Toll Services, and IntraLATA Access Services. The new surcredit or surcharge percentages are applied to the tariffed rate of the individual services that comprise each of the three service groups (IntraLATA toll, access, and exchange). The adopted surcharge or surcredit percentage is applied to the tariffed rate for the services in each service group. This is the price that the customer pays for the respective service for the following year.
In D.00-09-037 and D.01-09-063 we used Rule 33 and Tariff 38 as the mechanisms for the payment of Pacific's and Verizon's local competition implementation infrastructure costs by their customers. Rule 33 and Tariff 38 surcharges/surcredits appear as separate line items on Pacific's and Verizon's bills respectively.77 ORA argues that since the line items have already been established, there is no need for the Commission to authorize the creation of new line items, thus avoiding billing system modification expenses.
We are persuaded by ORA's arguments. Pub. Util. Code § 454 gives the Commission statutory authority to establish rates and charges for regulated telecommunications companies. Commission decisions provide precedents for service standard violations generating surcredits to ratepayers, as described by ORA,discussed supra. Additionally, paying into the General Fund does not provide the equitable outcome that payment to the ratepayers provides. Unlike the ratepayers, the General Fund has no investment in ILEC OSS infrastructures and is not directly affected by OSS outcomes. For the above reasons, for Tier II incentive payments, we will adopt ORA's basic proposal to make payments to the ratepayers.
However, using Rule 33/Tariff 38 mechanisms will delay payment disbursements to the ratepayers. For example, a payment incurred in January 2003 would not be reflected in the surcredits to be disbursed until 2004. In addition to the Rule 33/Tariff 38 mechanism delays, there are built-in delays for performance result and incentive payment calculations. Payments are not due until about seven weeks after the end of the month in which the performance occurred.78 As a consequence, for example, performance incentive payments for August 2002 through July 2003 would be the most recent twelve-month's incentive payments available for the Price Cap filing in October 2003. The total Tier II incentive payment amounts for these twelve months would then be credited to the ratepayers in equal monthly increments from January 2004 through December 2004.
Given these delays, we are concerned that the performance incentives plan would not provide a timely incentive for an ILEC to provide good performance. To the extent possible, payments should immediately follow poor performance when it is identified. However, we realize that there would be numerous logistical and efficiency problems in creating an entirely new structure to provide immediate payments to each individual ratepayer. To remedy the payment time-lag, we will adopt ORA's proposal with the modification that incentive payments be made monthly into a memorandum account. However, payment disbursements still would be delayed. Recognizing a basic economic principle, that a monetary amount received in the future has less value to the recipient as the same amount received in the present, we will require that the payment account accrue interest. A ratepayer should be "indifferent" to an amount received in the future versus an amount received now if the future amount were to be increased as if the ratepayer had spent or invested the money now. Additionally, ratepayers should be "indifferent" to future payments if they perceive equity when comparing the interest rates they receive to the interest rates they pay to Pacific and Verizon. Consequently, we will require the ILECs to make monthly payments into an interest-bearing memorandum account with an interest rate equal to the tariffed rate the respective ILEC's charge their customers for late payment. The interest shall be compounded monthly, and interest accrual shall begin immediately after the incentive payments are due and shall continue to accrue on all amounts not yet credited to the ratepayers.
It is not our intent to disadvantage ratepayers as a result of the ILECs paying into the performance incentive memorandum account. Therefore, we shall require that Pacific Bell and Verizon identify in their respective separated intrastate results of operations monitoring reports79 an adjustment clearly identifying the annual performance incentive payments. This adjustment shall remove from the California intrastate results of operations, and the earnings monitoring reports, the payments made to the memorandum account.
5. Root Cause Analysis and Expedited Dispute Resolution
Pacific proposes that it be allowed to "use Root Cause Analysis to demonstrate that an apparent out-of-parity condition was attributable to an atypical event beyond the reasonable control of Pacific Bell." Pacific Plan at 14. Pacific would have the burden of proof, and if it met that burden would be able to exclude the condition (performance result) from its incentive payments. Id. at 15. The CLECs concur with the root cause analysis Provisions Pacific proposes except for a concern about force majeure events. CLEC Open. Comm. at 35. The CLECs argue that force majeure should not allow Pacific to treat its customers preferentially, and request that parity measures still be eligible for incentive payments. For example, in the event of force majeure service outages, the CLECs believe that their customers should regain service at parity with Pacific's customers.
We agree with the CLECs' position here because discrimination in restoring normal OSS services could damage competition. Following the recent terrorist attacks use it in in a than the in the than the use with, we believe customers have become especially sensitized to infrastructure recovery issues, and an ILEC could easily gain an advantageous reputation for superior recovery and robust service. For these reasons we will require that the parity assessment and incentive payment provisions continue for parity measures during force majeure events and the ensuing recovery period.
In 1999, Pacific and the CLECs were apparently close to an agreement on expedited dispute resolution (EDR) provisions. However, upon passage of Senate Bill 960 the CLECs introduced adaptations that Pacific rejected.80 Even though there were many points of agreement, an implementable EDR process is not currently available for the incentives plan. Numerous issues critical to an effective EDR process are either unresolved or unacknowledged. For instance, parties have not been able to agree on what, if any, procedural timelines and rights they are willing to waive in the interest of expedited process. Moreover, it is not clear what resource impact a formal EDR process will have on this Commission.
Pacific's current position is:
Any dispute regarding whether a Pacific Bell performance failure is excused will be resolved, through negotiation, through a dispute resolution proceeding under applicable Commission rules or, if the Parties agree, through commercial arbitration with the American Arbitration Association. Pacific Plan at 15 (March 23, 2001).
However, there is nothing about what Pacific offers here that is "expedited." If the incentives plan we adopt did not have this paragraph, it would be no different than if it did. Given the need for further examination and discussion of these essential issues, we cannot order an EDR process at this time. We urge the parties to address these unresolved issues no later than at the conclusion of the initial implementation period. Until an EDR process is implemented, the ILECs must automatically make incentive payments as indicated by the incentive plan we adopt. The parties must use currently available Commission procedures in any disputes regarding these payments.
6. Payment Delays for New Measures
Pacific proposes that when new measures are introduced, payments not be made on performance failures until the fourth month:
None of the payment provisions set forth in this plan will apply during the first three months after a CLEC first purchases the type of service or unbundled network element(s) associated with a particular performance measurement or introduction of a new measure. Pacific Plan at 14.
The CLECs partially agree. They agree that upon introduction of a new measure, the results will not be subject to incentive payments until the third full month of reportable results. CLEC Open. Comm. at 33. However, we note that new measures are adopted by the Commission after the parties have performed these initial trials. Once the Commission adopts these new measures they may produce incentive payments immediately. Prior to this implementation, however, the JPSA adopted in D.01-05-087 must be modified for a new measure to be included in the incentives plan. Proceedings to modify the JPSA and D.01-05-087 must be completed before any new measure can produce payment. It is more appropriate for the Pacific-CLEC agreement regarding new measure implementation to be included in JPSA modification proceedings. Therefore, we do not need to include this provision in the incentives plan, and we decline to do so.
Regarding Pacific's desire to be free of liability for poor performance for the three months after a CLEC first orders a new service, we do not find consensus among the parties. The CLECs object and point out that the first months can be the most critical months for a CLEC. CLEC Open. Comm. at 34. We agree. We are particularly concerned about the viability of new small CLECs who may invest precious resources in marketing new services. For an ILEC to be free of liability for three months could easily put such new competition in jeopardy. For this reason, we decline to adopt this provision.
7. Performance Assessments
As Pacific worked to implement the Interim Opinion performance assessment requirements, it found a few problems. Pacific proposes modifications to correct those implementation problems. Pacific Open. Comm. at 27-28. Specifically, Pacific requests three changes: (1) that an additive constant be used for all log transformations, (2) that the Modified t-test be applied to Measure 44 without transformations, and (3) that the Fisher's Exact Test be used for all percentage-based results regardless of sample size. No party opposes these changes. For the reasons cited by Pacific, we adopt these changes. Id.
29 Payment caps in New York, Texas, Kansas, and Oklahoma are 36% of net return. Bell Atlantic New York Order ("FCC BANY Order"), 15 FCC Rcd at 3971, ¶ 436; SWBT Texas Order ("FCC Texas Order"), 15 FCC Rcd at 18354, ¶ 424; SBC Kansas-Oklahoma Order ("FCC Kansas-Oklahoma Order"), 16 FCC Rcd at 6237, ¶ 274. The payment cap in Massachusetts is 39% of net return. Verizon Massachusetts Order ("FCC Massachusetts Order"), 16 FCC Rcd at 9118, ¶ 241 and fn. 769. The payment cap in Connecticut is proportional to the New York amount, based on the relative number of lines. Verizon Connecticut Order ("FCC Connecticut Order"), __ FCC Rcd at __, ¶ 76; Application By Verizon New York For Authorization To Provide In-Region, Interlata Services In Connecticut, at 78 (April 23, 2001). Payment caps have yet to be established in Pennsylvania. Verizon Pennsylvania Order ("FCC Pennsylvania Order"), __ FCC Rcd at __, ¶ 130, fn. 445. 30 Verizon proposes approximately $20 million, $30 million, and $40 million annual payment caps in the first, second, and third years of incentive plan operation. In contrast, given that Verizon's net return from local exchange service is $461,450,000, a cap consistent with the Pacific and CLEC proposals in California, and consistent with Section 271 approvals in other states, would be thirty-six percent of this amount, or about $166 million. See Appendix C (ARMIS 43-01 Cost and Revenue Table). 31 The FCC lists other remedies that can be applied. See FCC BANY Order, ¶ 435. 32 With Pacific's annual net return at $1.5 billion and a proposed monthly cap of $10 million, if Verizon had set a comparable procedural cap relative to its net return of $461 million, it would be $3 million per month, would exceed the absolute cap for the first two years, and would be about the same as the absolute cap for the third year. 33 Pacific Bell Telephone Company's (U 1001 C) Opening Comments on Performance Remedies Plan (May 18, 2001) at 22-23 ("Pacific Open. Comm."). 34 While both ILECs propose a conditional 0.20 critical alpha level, their proposals only extend to consecutive failures, which increase Type II error relative to Type I error. We discuss this further in a subsequent section below. 35 The actual percentage is greater than ten percent as we discuss later in this decision, but for the purposes of illustration here we use the ten percent figure. 36 For example, out of 1000 statistical tests, with a critical alpha of 0.10, in the first month we would expect 100 failures to be identified even though true parity exists. Because these errors are random under parity, we would not expect all the same to be identified the second month. We would again expect 10 percent to be identified, resulting in 10 remaining failure identifications. The third month we would again expect ten percent of the remaining identifications to be identified, resulting in one remaining identification. This resultant critical alpha can be calculated by multiplying the monthly critical alphas (0.10 x 0.10 x 0.10 = 0.103 = 0.001, or 0.1%). 37 106 = 0.000001, or 0.0001 percent. 38 These estimates were based on selected alternative hypotheses. That is, two estimates were made: What would the Type II error be if (1) performance was 50% worse for the CLECs, or (2) performance was 100% worse for the CLECs. 39 Initial Report on OSS Performance Results Replication and Assessment, ("Init. Rept. on OSS Perf."), California Public Utilities Commission, Telecommunications Division, June 15, 2001. 40 We note that we have already built in considerable protection against random variation. As we discussed in the Interim Opinion, even when OSS performance to CLEC customers is worse than performance to ILEC customers, a performance failure is not identified unless the result passes a statistical test. All the instances where CLEC customers receive worse OSS performance are essentially "forgiven" if the statistical test criteria are not met. For example, in December 2001, individual CLECs collectively received poorer service twenty-eight percent of the time. Since the 0.10 critical alpha criterion is only met by about eight percent of the results, our "forgiveness" rate is about twenty percent. 41 Verizon's illustrations are reproduced here in Appendix D. 42 See Init. Rept. on OSS Perf. at 2. 43 Ex Parte contact on July 25, 2001, by Ed Kolto, General Attorney, and Eric Batongbacal, Executive Director-Regulatory, Pacific Bell Telephone Company, with Lester Wong, Advisor to Commissioner Bilas. http://www.cpuc.ca.gov/published/proceedings/I9710017.htm. 44 The FCC appears to share this position. See FCC BANY Order, ¶ 440, fn. 1350 and App. B. ¶ 18, fn. 51. 45 Under optimal statistical test conditions and "perfect parity service," statistical test results for all service are subject to random variation. Pacific's use of the term "ultra-superior service" seems misplaced for Scenario 1, as the term excludes random variation from the upper ten percent and contradicts the notion of "perfect parity service." 46 If 100 percent of the results that are not ultra-superior service fail, outcomes of less than ten percent (one percent of total) Type I errors are likely. Ten percent Type I errors is likely under parity conditions for the portion of results that are not ultra-superior service. However, when 100 percent of these results fail, it is more likely that there are fewer Type I errors, if any. 47 These simulations were created for different purposes. They were created to provide information on how the different plans would function under potential future parity and non-parity conditions. One particular problem Pacific had was in simulating parity outcomes for the average-based performance measures. As a practical matter, Pacific had to assume lognormal distributions, which would normalize with a lognormal transformation. However, we have previously documented evidence showing that while average-based distributions moved towards normality with the transformation, they did not end up truly normal. Interim Decision, App. J, Attach. 4. As a consequence, the simulation does not depict a distribution sufficiently accurate for selecting the relatively small percentage margins that are needed for the mitigation plans. 48 See the discussion in the Interim Opinion, specifically Figure 4 at 66, and generally at 59-69 and 83-98 (January 18, 2001). 49 The default critical alpha level is 0.10 as specified in D.01-01-037. 50 $291,080/$550,059,120 = 0.000398, or less than 0.04 %. 51 ($7,415,506 x 12)/$1,527,942,000 = 0.0582, or less than 6 %. 52 These relative rates are illustrated in staff's June 15, 2001 report. Figures C and E illustrate aggregate and CLEC-level failure percentage of approximately 15 and 10 percent, respectively. Init. Rept. on OSS Perf. at 16 and 18. These differences are due to the greater statistical power for tests for the larger samples (aggregate samples). 53 March, April, and May, 2001 overall aggregate failure rates are 75, 81, and 39 percent higher than the respective CLEC-level rates for these months. March aggregate and CLEC-level failure rates are 12.9 and 7.4 percent, respectively. April aggregate and CLEC-level failure rates are 11.4 and 6.3 percent, respectively. May aggregate and CLEC-level failure rates are 8.9 and 6.4 percent, respectively. These figures are taken from performance reports requested by staff from Pacific. 54 The mathematical basis for this graph is presented in Appendix E. 55 While Pacific and Verizon will be subject to the same incentives plan model, they will have different base amounts to adjust for differences of scale between the two ILECs. The base amounts will be set so that the plan produces the same relative payment (percentage of net return) for similar performance levels. These amounts will also be adjusted to account for month-to-month variation in CLEC OSS activity to ensure that such volume changes do not increase or decrease payment rates even though performance rates are constant. 56 For example, see the FCC's Local Competition First Report And Order for references to concern about "gaming" in other areas. Implementation of the Local Competition Provisions of the Telecommunications Act of 1996, CC Docket No. 96-98, First Report and Order, 11 FCC Rcd 15499, (1996) (Local Competition First Report and Order). ¶¶ 239, 884, 889, 1040, 1101, and Separate Statement of Commissioner Susan Ness at D2. 57 We also recognize that a CLEC may also be able to "game" the performance incentives system. For example, a CLEC could hold its orders and submit them all at once at the end of the month. The OSS overload would cause the CLEC's orders to be more slowly processed than the ILEC's orders because the ILEC's orders would be spread across the rest of the month. This particular example may not be a real concern for several reasons. One reason is that such a strategy would be self-defeating for the CLEC. Submitting orders to solicit deficient service for its customers could cause the CLEC to lose too many customers. Additionally, we can include provisions to exclude such intentional "clustering" of orders from penalty payments. The forecasting requirements proposed by several parties may adequately address this issue. Pacific Plan at 20-21; CLEC Plan at 18-19. 58 The resultant Type I error when all three out of three tests must fail individually at the 0.10 level to reach a performance failure decision: p = 0.103 = 0.001; The resultant Type II error when three out of three tests with individual Type II errors of 0.30 must fail to reach a performance decision: p = 1 - (1 - 0.30)3 = 0.657. 59 There are two possible outcomes for one coin toss: H ("heads") or T ("tails"). The probability of a "heads" is one out of two chances, expressed as one-half, 50 percent, or 0.50. There are eight possible outcomes for three coin tosses: TTT, TTH, THT, HTT, HHT, HTH, THH, and HHH. As there is only one three-headed outcome (HHH), the probability of three heads is one out of eight chances, expressed as one-eighth, 12.5 percent, or 0.125. 60 Again, there are two possible outcomes for one coin toss: H ("heads") or T ("tails"), with the probability of a "heads" being one out of two chances, or 0.50. Again, there are eight possible outcomes for three coin tosses: TTT, TTH, THT, HTT, HHT, HTH, THH, and HHH. However, since seven of these outcome have at least one "heads," the probability is seven out of eight chances, expressed as seven-eighths, 87.5 percent, or 0.875. 61 Requiring five out of six months to fail at the 0.20 critical alpha level produces a net critical alpha of 0.0016 (Type I error), and assuming a single-month beta of 0.30, produces a net beta of 0.580 (Type II error). Staff determined these values using a binomial calculation. 62 When individual CLEC results do not meet sample size minimums, they are aggregated with other sub-minimum CLEC samples to create a CLEC small sample aggregate. D.01-01-037, App. C at 4. 63 Two-page document setting forth the assumptions used to code each plan for the simulation. Distributed by Verizon Communications by electronic mail to the active technical experts on the service list. Originally titled "VZASSUMPTIONS.doc." 64 As listed in Pacific's performance reports using the Interim Opinion statistical model. The mean of the logs for each result was transformed back into days for the performance figures listed here. The non-transformed means were 20 days for CLEC A and 12 days for both CLEC B and Pacific. 65 For Pacific's performance and payments, the correlations between payment amounts and failure rates are 0.42 for Pacific's plan, 0.13 for the CLECs' plan, -0.12 for Verizon's plan, and -0.01 for ORA's plan. Only Pacific's correlation is significant at the 0.10 level (N = 12). The graphs at the end of Appendix B illustrate the relationship between monthly payment amounts and failure rates. 66 The document states that Pacific, GTE, and the CLECs agreed to these exclusions. The document was resubmitted following the February 7, 8, and 9, 2001, workshops and was received in this proceeding as 2000 GTE Workpaper #13 on April 2, 2000. 67 See W. Hays, Statistics at 717-720 (5th ed. 1994), for a statistical explanation. See also E. Ghiselli, J. Campbell, and S. Zedeck, Measurement Theory for the Behavioral Sciences, at 162-168, 261 (1981). 68 The agreement reads: "The parties agree that monetary performance incentives are not the exclusive remedy available to address Pacific's service problems." Late Filed Joint Comments Regarding Report on Performance Incentives, filed October 5, 1998, by Pacific Bell and the CLECs, at 48. Verizon (then GTE California Incorporated) participated in some discussions that led to the joint motion. Id. at 1. However, Verizon did not participate in incentives discussions, and was not a party to the motion itself. Id. at 1, fn. 1; Motion to Accept Joint Comments Regarding Report on Performance Incentives, filed October 5, 1998, Pacific Bell and the CLECs, at 1, fn. 1. 69 BANY Order at ¶ 430, 15 FCC Rcd 4165. 70 Id. 71 The Commission has previously used financial incentive mechanisms to encourage utility behavior. See In the Matter of Used Household Goods Transportation by Truck 1998 Cal. PUC LEXIS 431; In Application of Pacific Gas and Electric Company 12 CPUC2d 604 (1983); and CPUC Resolution E-3657 (February 17, 2000). 72 The JPSA Opinion contained several requirements that needed to be completed before the due date of the 15th of each month was shifted to the 20th. Id. Upon staff inquiry, Pacific personnel reported that those conditions were met and Pacific is currently reporting on the 20th of each month. 73 For example, Measure 42, Percent of Time Interface is Available, is only tracked at the CLEC industry-aggregate level since the interface either works and is open to all CLECs, or it does not work and is closed to all CLECs. 74 Schedule Cal. P.U.C. No. A2.1.33 - Billing Surcharges of Pacific's tariffs ("Rule 33"). 75 Schedule Cal. P.U.C. No. 38 - Billing Surcharges of Verizon's tariffs ("Tariff 38"). 76 D.00-09-037 authorized Pacific to recover $87.5 million in claimed Local Competition Implementation Costs from California ratepayers. Similarly, D.01-09-063 authorized Verizon to recover $12 million in claimed costs. 77 For example, ORA points out that the Rule 33-related line item is located in the Taxes and Surcharges section on Pacific's bills as item 6 "rate surcharge." 78 For example, performance results for July are due August 20th, and incentive payments generated by those results are due 30 days later, September 19th. Supra. 79 The Pacific Bell intrastate separated earnings report is referred to as the Intrastate Earnings Monitoring Report (IEMR) and has the NRF monitoring report code PD-01-27. Verizon's report is entitled the Recorded and Adjusted Separated Results of Operations Report and has the NRF monitoring report code GD-04-01 80 CLEC Open. Br. at 39 - 53 (March 22, 1999); Pacific Open. Br., at 26-39 (March 22, 1999); CLEC Reply. Br. at 26-42 (April 5, 1999); and Pacific Reply. Br. at 18-23 (April 5, 1999).